
Rise of Vector Databases
If have recently heard of Vector Databases and wondering what the hype is al about, this note will help to demystify and may justify the hype.


(cover image generated by Midjourney AI)
Surge in Hype Around Vector Databases
There is a sudden rise in the popularity and adoption of vector databases. This trend is exemplified by significant funding rounds secured by leading vector database companies. Pinecone, a prominent player in the field, raised $100 million with a valuation of $750 million. Similarly, Weaviate secured $50 million at a valuation of $200 million. Chroma obtained $18 million in seed funding with a $75 million valuation. All of these developments have occurred within the past month, indicating the hype around vector databases.
Several vector databases have gained recognition and popularity among developers. Milvus and Pinecone, are high-performance vector databases designed to facilitate large-scale similarity searches. Weaviate, on the other hand, is an open-source vector database that offers robust capabilities for storing and managing vector data. Other notable vector databases are Qdrant and Chroma.
Brief Intro to Vector Databases
A vector database is optimized for storing and querying high-dimensional vectors or in simple terms arrays. If you are to brush up on your math, Vectors are typically used to represent data points in a multidimensional space. For example, a vector could be used to represent the features of a product, such as its price, weight, and color.
Vectors are used in natural language processing (NLP), computer vision, and recommender systems. In NLP, vectors are used to represent words, phrases, and their relationships (called word embeddings). In recommender systems, vectors are used for user & item embeddings, which are representations of users, items they bought, and other preferences.
While Vectors can be stored in files and can be indexed in memory, Vector databases make it easy to do that at scale. Another question is why not use a SQL or No-SQL database? Vector databases are purpose-built to store and operate on vector data, and also offer a number of advantages over traditional relational databases when storing vectors. They are much more efficient at storing and querying large numbers of high-dimensional vectors. They support specific vector operations, such as similarity search and distance calculation, apart from highly performant CRUD operations.
Why is this sudden interest?
The potential of OpenAI's ChatGPT, GPT-4, and large language models (LLMs) in general has opened up numerous possibilities. While off-the-shelf LLMs trained on publicly available datasets may suffice for individuals and generic use cases, businesses require the LLMs to be more specific so that they are accurate and effective to use in their internal applications.
Hence, there is an urgency to customize LLMs with domain-specific data. According to this expert.ai survey report, more than one-third of surveyed enterprises (37.1%) are already planning to train and customize language models to suit their unique requirements.
When it comes to customizing LLMs for enterprise use, there are multiple approaches available. Training an LLM from scratch, however, is complex and costly, making it an impractical option for most organizations. Fine-tuning and ICL/RAG (In-Context Learning/Retrieval-Augmented Generation) are popular alternatives, with RAG gaining prominence. The detailed comparison between this approach is beyond the scope of this article.
The RAG approach involves passing domain-specific data as part of the context, enabling the LLM to understand and generate responses tailored to the domain. It's similar to how one would paste an article or document in the chat window while using ChatGPT on a browser and then ask questions.
However, this approach has limitations. It quickly reaches the context limits of ChatGPT (around 4k tokens or roughly 1000 words) and requires passing domain knowledge for every new session since ChatGPT does not retain the context from previous sessions.
This is where vector databases come into play. At a high level, vector databases can be viewed as providers of long-term memory when interacting with LLMs. They allow for efficient storage and retrieval of domain-specific information, enhancing the LLM's contextual understanding and improving its responses.
Vector Databases with LLMs
The workflow of using Vector databases with LLMs typically involves two main steps: populating the Vector database and then using it (known as RAG) while interacting with the LLM.
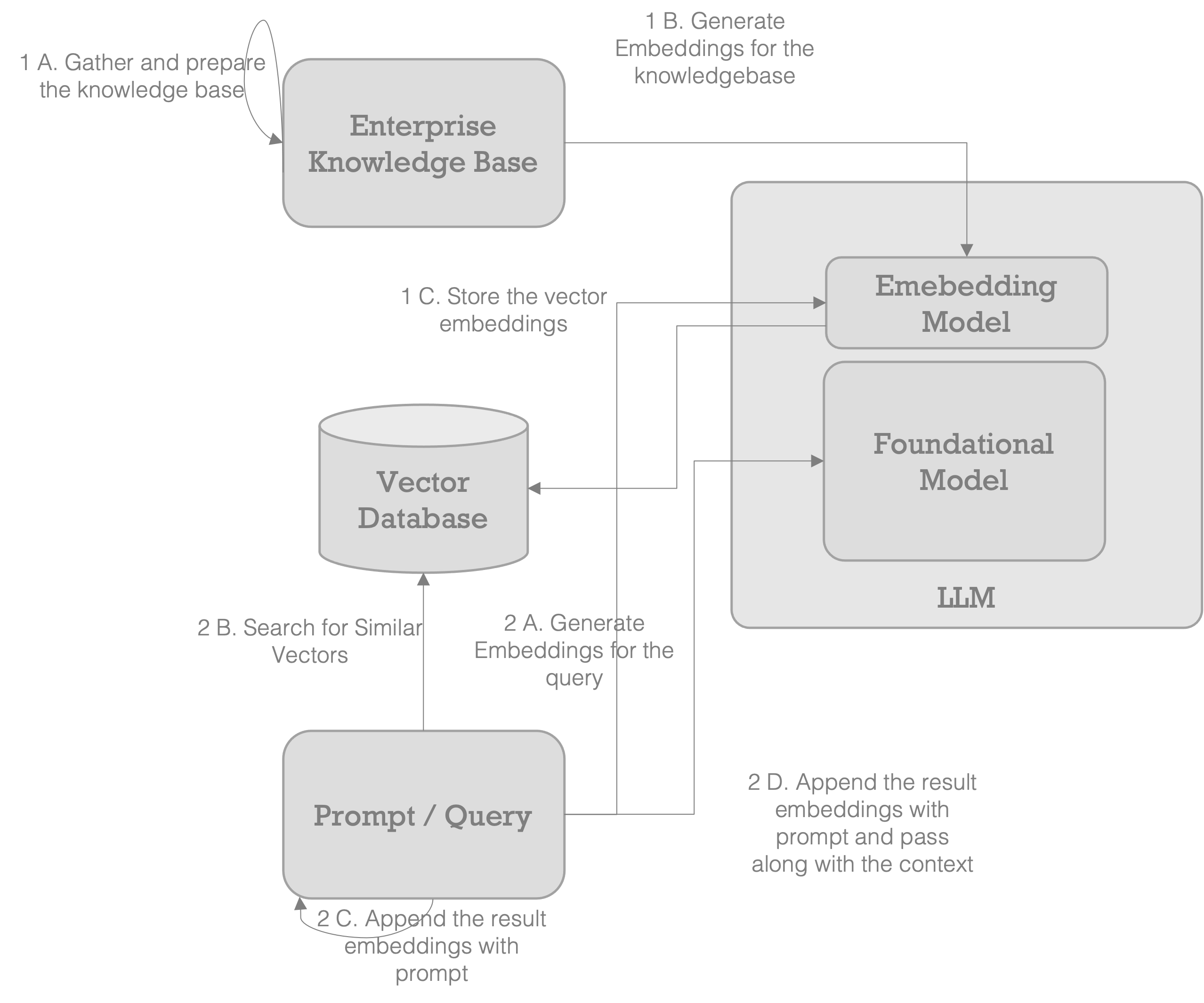
Populating the Vector Database:
Gather domain-specific knowledge such as documents, text, webpages, or any other relevant data sources.
Utilize an embedding technique (such as Glove or Word2Vec) or an Embedding model, such as text-embedding-ada-002, to generate embeddings for the collected data.
Store these vector embeddings in a Vector database, associating each embedding with its corresponding source item. This enables efficient storage and retrieval based on similarity.
Interacting with LLM:
Craft the prompt and generate word embeddings for the prompt text using the same embedding creation method used in the previous step.
Query the Vector database, searching for related embeddings based on the embeddings generated from the prompt. This step aims to find similar or relevant documents or information.
Combine the resulting embeddings retrieved from the Vector database with the embeddings of the prompt. This merging of embeddings enhances the context provided to the LLM, incorporating domain-specific knowledge or related information into the input.
Pass the combined embeddings, representing the augmented context, to the LLM model. The LLM utilizes this contextual information to generate a response or output that aligns with the specific domain or topic of interest.
As you can see, the context has only the embeddings relevant to the prompt, and not the entire document corpus of the enterprise. Vector databases make this possible by searching and retrieving the relevant embeddings for a given prompt, by which the use of Enterprise data with LLMs become very efficient.
What is next for Vector Databases?
Vector databases currently have such hype when NoSQL databases first emerged. While they share similarities and prove useful, Vector databases remain niche, and standalone Vector database management systems face challenges in thriving in the future.
One possible evolution is Integration with document databases. As vector databases become more popular, it is likely that document databases will start to integrate vector operations. This would make it easier for developers to use vector databases without having to learn a new database technology.
For example, ElasticSearch already supports Vector operations, and PostgreSQL offers the pgvector extension for Vector storage and operations. In fact, AWS RDS PostgreSQL supports pgvector to store vector embeddings when using Amazon Bedrock.
To conclude, Vector databases are super useful, in the near-term horizon, and they are quite useful when using LLMs within enterprises.